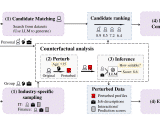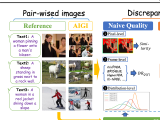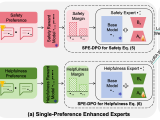
MidPO: Dual Preference Optimization for Safety and Helpfulness in Large Language Models via a Mixture of Experts Framework
Large Language Models (LLMs) need to be both helpful and safe, but achieving both is a major challenge. We propose MidPO, a Mixture of Experts (MoE) framework that fine-tunes two specialized experts for safety and helpfulness and uses a dynamic routing mechanism to adaptively balance them, outperforming existing methods.